Lambdaで大きなファイルを扱う場合、ファイルの置き場所としてS3を使う場合がよくあると思います。
しかし実は別の選択肢として、Amazon EFS (Amazon Elastic File System) というものがあります。簡単に言うと、ネットワークディスクのサービスで、これをLambdaにもアタッチできるわけです。詳しいメリットや構築方法などは以下をご参考にしてください。
またAWS公式のブログにも比較がありました。S3は “Fast”、EFSは “Very Fast” とのことでしたが、具体的な比較はありませんでした。
今回はこのS3とEFSをどう選んだらよいのかという参考にするため、「1つの大きなファイルをダウンロードする」というパターンと「大量の小さなファイルをダウンロードする」というパターンの2通りについて実際にダウンロード速度を比較してみました。
環境
Lambdaのスペックは以下の通りです。
- Memory: 512MB, 1024MB, 3008MB
- Ephemeral storage: 1228MB
- Runtime: Python 3.12
- Architecture: arm64
少量の大きなファイルのダウンロード
以下のコマンドで1GBのファイルを生成しました。
cat /dev/urandom | base64 | head -c $((1024*1024*1024)) > ~/rand_1g.txt
ダウンロード速度はS3, EFSそれぞれ以下の処理で計測しました。実際にLambdaのエフェメラルストレージに保存を行っています。
def download_file_from_s3(bucket, key):
output_path = f'/tmp/{key}'
start_time = time.time()
s3_client.download_file(bucket, key, output_path)
total_time = time.time() - start_time
os.remove(output_path)
return total_time
def download_file_from_efs(dir, file):
input_path = f'{dir}/{file}'
output_path = f'/tmp/{file}'
start_time = time.time()
shutil.copy(input_path, output_path)
total_time = time.time() - start_time
os.remove(output_path)
return total_time
結果は以下の通りでした。単位は秒です。
| ダウンロード元 | 512MB | 1024MB | 3008MB |
|---|---|---|---|
| S3 | 19.03 | 12.76 | 12.09 |
| EFS | 20.37 | 18.46 | 3.04 |
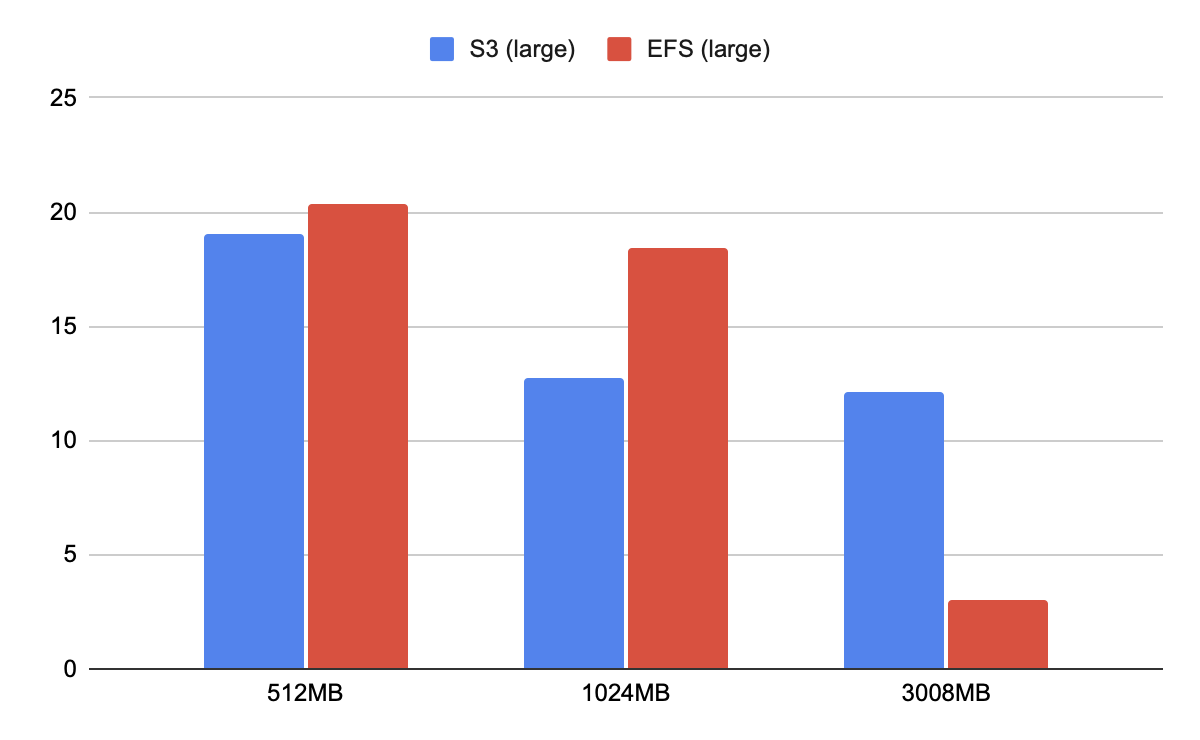
ここで注意点として、メモリ3GBにおけるEFSの結果が異様に速くなっています。以下がリクエスト1つずつの結果なのですが、最初を除くと0.7s〜2.5s程度を行ったり来たりしています。以下は推測ですが、EFSのキャッシュがメモリ上に残っており、さらに /tmp がメモリ上の仮想ディスクであるため、そこのコピーが一瞬で終わっている可能性がありそうです(またはファイルの実態まではコピーされていないなどもありえそうです)。
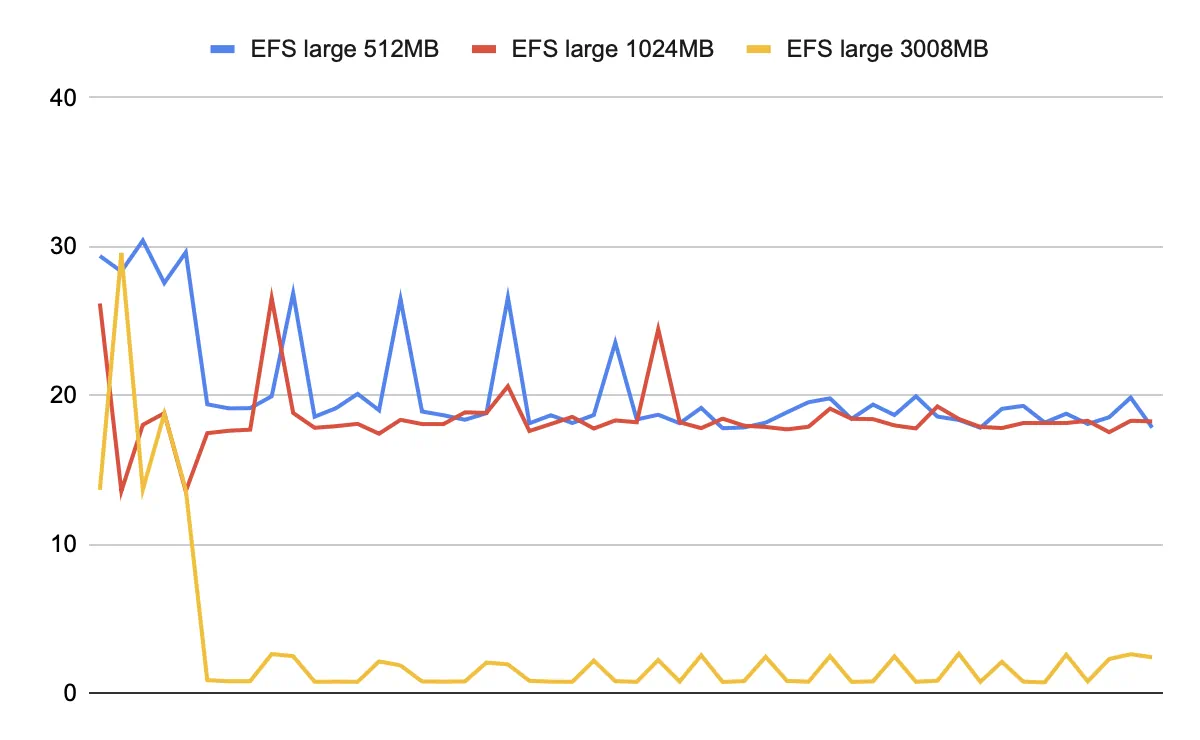
ちなみに3008GBの場合のEFSの結果から3秒未満を除いたものの平均をとると17.87秒でした。Lambdaのスペックを上げてもEFSのダウンロード速度はほぼ上がらないと言えそうです。S3の場合はメモリを1GBまで上げればスペックがボトルネックになることはなさそうです。
大量の小さなファイルのダウンロード
以下のコマンドで10KBから100KBまでの1000個のファイルを生成しました。合計サイズは55MBです。
for i in $(seq 1000); do
FILENAME=$(cat /dev/urandom | base64 | tr '/' '_' | head -c 16).txt
cat /dev/urandom | base64 | head -c $(((RANDOM % 10 + 1) * 10 * 1024)) > ${FILENAME}
done
生成したファイルを特定のprefix配下にすべて配置し、以下のようにまとめて取得しました。boto3ではS3上のファイルを再帰的に取得する関数が見つからなかったため、オブジェクトのリストを取得してその各々をダウンロードしています。
def download_directory_from_s3(bucket_name, directory_prefix):
directory_prefix = directory_prefix.rstrip('/') + '/'
output_dir_path = '/tmp/small'
os.makedirs(output_dir_path, exist_ok=True)
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor:
paginator = s3_client.get_paginator('list_objects_v2')
for page in paginator.paginate(Bucket=bucket_name, Prefix=directory_prefix):
for obj in page.get('Contents', []):
file_key = obj['Key']
output_path = os.path.join(output_dir_path, file_key[len(directory_prefix):])
executor.submit(s3_client.download_file, bucket_name, file_key, output_path)
total_time = time.time() - start_time
shutil.rmtree(output_dir_path)
return total_time
def download_directory_from_efs(directory_path):
input_path = directory_path.rstrip('/') + '/'
output_dir_path = '/tmp/small'
start_time = time.time()
shutil.copytree(input_path, output_dir_path)
total_time = time.time() - start_time
shutil.rmtree(output_dir_path)
return total_time
結果は以下の通りでした。
| ダウンロード元 | 512MB | 1024MB | 3008MB |
|---|---|---|---|
| S3 | 29.84228375 | 13.84117228 | 6.624918976 |
| EFS | 5.047228951 | 4.186467919 | 2.712615299 |
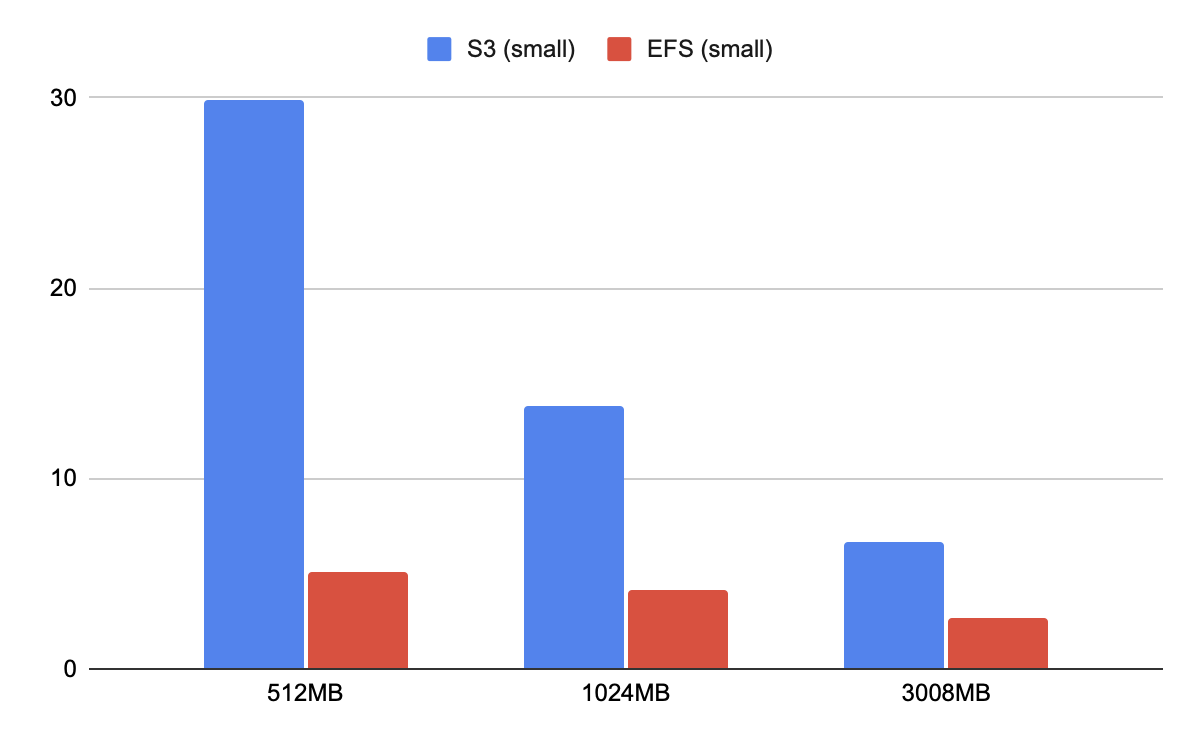
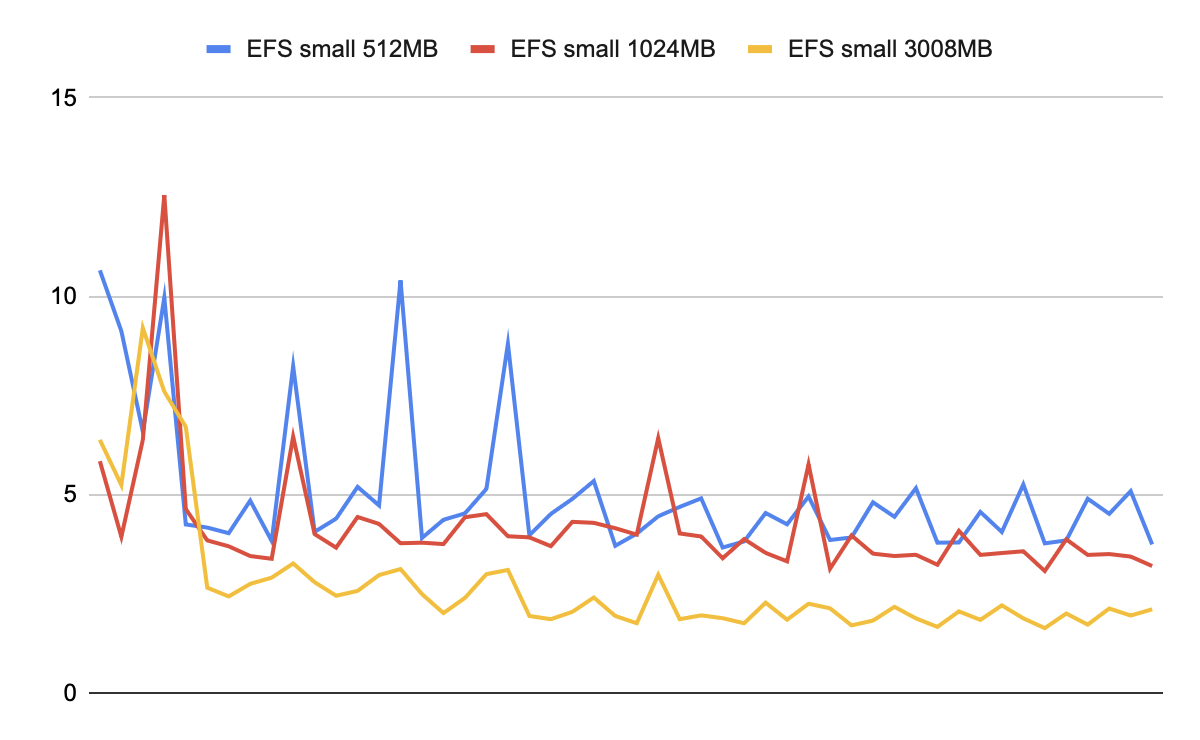
S3の方はCPU(またはメモリ)がボトルネックになっているようで、スペックを上げるとその分時間が短縮されました。スペックを上げたLambdaにおいても並列数は10のままなので、ここをチューニングすることでS3ではさらに高速化が図れる可能性はありそうです。
こちらもEFSは何らかのキャッシュが効いていそうな挙動を示していました。ただ、キャッシュが全く効かない条件で比較したとしても、低スペック時のS3ダウンロードよりEFSの方が確実に速いということは言えそうですし、いい感じにキャッシュを効かせてくれるとするならばそれはEFSのメリットかなと思います。
まとめ
LambdaからS3とEFSのそれぞれからのファイルダウンロード速度を比較しました。S3はLambdaのスペックに大きく影響を受けました。EFSはキャッシュが効いているような挙動が確認され、それぞれ特徴がありそうです。
またS3は並列数を上げることでより高速化が見込めますし、EFSはファイルの保存量によってスループットも変わるそうなので、今回の条件においても変化があるかもしれません。今回は細かいチューニングまでしていませんが、結果を見る限りは大きなファイルはS3から、大量のファイルはEFSからの方がパフォーマンスが高そうでした。特に大量のファイルを扱う場合、今回はS3のアクセスを並列化しましたが、逐次的にファイルにアクセスする場合は単純に並列化できませんので、その場合はEFSがかなり優位となりそうです。
ご自身に合った条件にて比較していただくとまた違った結果が見られるかもしれませんので、もし新しい発見があればコメントいただけると嬉しいです。